
Advanced Data Downloading With AWS Step Functions
04 Mar 2021Last month I introduced you to the Step Functions Downloader Pattern. This article follows up with a more complex example which explores some limitations of the Step Functions Downloader Pattern.
In our previous example we retrieved a JSON object and stored it in a DynamoDB table. This example uses Map states to query multiple pages of an API in parallel, uses ResultSelectors to reduce the size of the API response down to the Step Functions maximum task output size, and aggregates the result before writing thousands of entries into DynamoDB.
Below you see the visualization of the state machine.
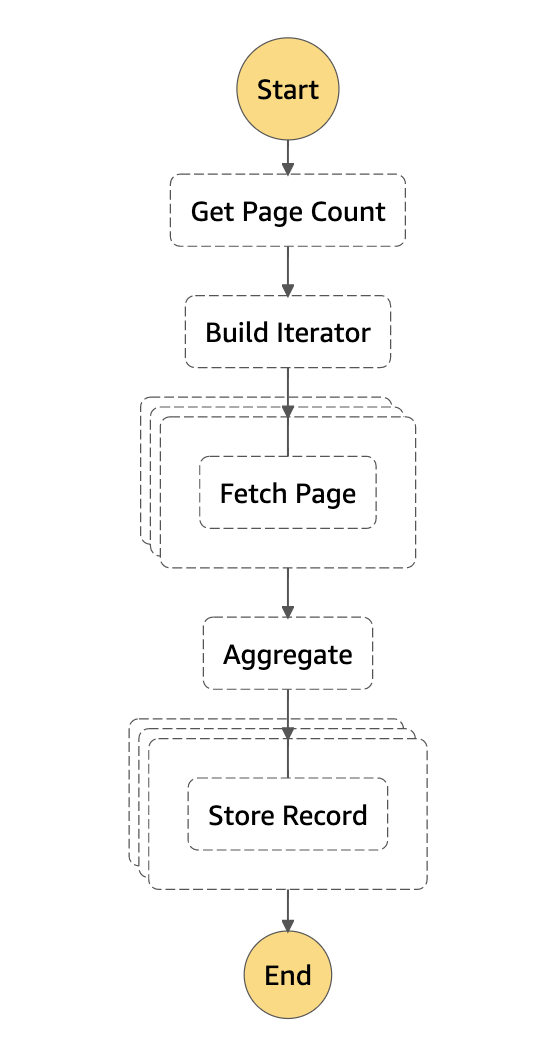
Involved in this state machine are the three task types API Gateway, Lambda, DynamoDB, as well as the Map State:
| Name | Type |
|---|---|
| Get Page Count | API |
| Build Iterator | Lambda |
| Fetch Pages | Map(API) |
| Aggregate | Lambda |
| Store Records | Map(DynamoDB) |
Whereas the tasks each perform an individual piece of work, the Map state helps us iterate and parallelize.
Interesting Pieces
We need to use a Lambda task to render a range array out of a number, because the API task expects multi-value query parameters.
Instead of queryParam=1 we have to provide queryParam=[1]. That means our Lambda function’s input is 5 and the according
output is [[1], [2], [3], [4], [5]].
At the end of the Fetch Pages step we need to use a ResultSelector to reduce the size of the output. In my case the pages
were larger than the 256 KB step output limit. Input and output processing are powerful concepts where I recommend to
read the official documentation.
There’s an upper bound of how much data this pattern can process. If the API returns more data than we can compress with the ResultSelectors, the state machine will fail. In my example I’m downloading data about market orders, but I’m only interested in the total volume per item being available. That’s why we have the aggregation step which performs a domain specific aggregation.
Tell me more about the API you’re using
The API that we use in this example is from the video game EVE Online, which has a player driven economy and also provides
an extensive API. Most items in the game can be traded on public
markets, which enables a trading playstyle. Tools that give you quick insight into aggregated data can get you a
significant advantage. For such a tool, we’re fetching and aggregating information about each item type that is listed
on the market. Below is an example for the item Tritanium which has the id 34.
{
"type_id": 34,
"price": 5.7,
"volume": 8592357682,
...
}
The market API is paginated and comes with an X-Pages header that we will use to run parallel requests.
You can try the endpoint we use in this example at https://esi.evetech.net/v1/markets/10000063/orders.
Let’s check up on prerequisites, and then dive right into the details.
Prerequisites
You should have read the introduction to the Step Functions Downloader Pattern which provides detailed explanations of some mechanisms we use here. Amongst others, we compared Standard and Express state machines, and looked into how one uses API Gateway as a proxy for 3rd party APIs. Check out Alex Hyett’s Getting Started with AWS Step Functions.
To get the most out of this article, you should also be familiar with AWS DynamoDB and AWS Lambda.
1. Get The Page Count
In this step we’re running a HEAD request, which won’t return any market data, but gets us the X-Pages header
that we need for building an iterator. As explained in the previous article, we’re using an API Gateway proxy
for 3rd party APIs.
You can see the abbreviated task definition for this step below.
"Get Page Count": {
"Type": "Task",
"Resource": "arn:aws:states:::apigateway:invoke",
"Parameters": {
"ApiEndpoint": "xxxxxxxxxx.execute-api.us-east-1.amazonaws.com",
"Method": "HEAD",
"Path": "/v1/markets/10000063/orders"
},
"ResultSelector": {
"pages.$": "$.Headers.X-Pages[0]"
},
}
The output of this step is an object with the page count:
{
"pages": "4"
}
This result tells us how many pages there are, which we need to transform into an iterator for the
API Gateway requests. Furthermore, the API Gateway integration requires multi-value query parameters, which means that
instead of queryParam=1 we have to provide queryParam=[1]. I ended up using a Lambda function to build a nested
array.
2. Build The Iterator
In this step we use a Lambda function, to build a nested array that we can use as an iterator for the Map state.
"Build Iterator": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:us-east-1:xxxx:function:RangeBuilder",
"Payload": {
"pages.$": "$.pages"
}
},
"ResultSelector": {
"iterator.$": "$.Payload"
},
}
This task definition takes the pages value ("4") as input for the Lambda function, and stores the result in the field iterator.
Below you can see the according Python code.
def lambda_handler(event, context):
# event: { "pages": "4" }
result = []
for i in range(1, int(event['pages']) + 1):
result.append([str(i)])
# result: [ ["1"], ["2"], ["3"], ["4"] ]
return result
3. Fetch Pages
Now that we have an iterator, let’s use a Map state to do download the data with dynamic parallelism.
What’s a Map state?
A Map state allows you to run any kind of task in parallel, when you provide an array that contains one record per iterator task that you want to execute. Map states don’t have unlimited concurrency, as Step Functions will start to wait for tasks to complete once you reach 40 concurrent tasks. In my tests there were up to 60 concurrent executions. You can however use nested workflows to increase concurrency.
Below you can see the Map state, and how we use the task input to provide a page parameter for the parallel tasks. We’ll look into the iterator tasks in the next section.
"Fetch Pages": {
"Type": "Map",
"ItemsPath": "$.iterator",
"Parameters": {
"page.$": "$$.Map.Item.Value"
},
"Iterator": {
"StartAt": "Fetch Page",
"States": {
"Fetch Page": {
...
}
}
},
}
With the two Map parameters ItemsPath and Parameters, we take the Map input and transform it into individual inputs
for each iterator task. ItemsPath takes the value from iterator (which is an array), and $$.Map.Item.Value
places each array value into the page variable. This means that each parallel execution now receives task inputs like
page: ["1"] or page: ["2"].
3.1 Fetch A Single Page
Now that we have turned the iterator into individual task inputs, let’s process each of them. This one is an API Gateway
task as we’ve seen it in the previous article,
but with the two new parameters QueryParameters and ResultSelector.
For this article I hardcoded the path to a single small market of EVE Online, because the larger ones had too much data.
"Fetch Page": {
"Type": "Task",
"Resource": "arn:aws:states:::apigateway:invoke",
"Parameters": {
"ApiEndpoint": "xxxxxxxxx.execute-api.us-east-1.amazonaws.com",
"Method": "GET",
"Stage": "prod",
"Path": "/v1/markets/10000063/orders",
"QueryParameters.$": "$"
},
"ResultSelector": {
"P.$": "$.ResponseBody..price",
"T.$": "$.ResponseBody..type_id",
"V.$": "$.ResponseBody..volume_remain"
},
"End": true
}
With the input parameter "QueryParameters.$": "$" we set the whole task input as query parameters. This means
that { page: ["1"] } becomes ?page=["1"]. QueryParameters requires multi value arguments. That’s why we needed
to use a Lambda function earlier for building a nested array of page numbers.
The response from the API looks like the following:
[
{
"price": 1587324.99,
"type_id": 1524,
"volume_remain": 17,
"some_other_field": "ignore_me",
...
}
...
]
We’re now facing the problem that most pages are larger than 256 KB, whereas AWS Step Functions limits task outputs to 256 KB.
With the parameter ResultSelector and the JSONPath .. operator, we can reduce the size of the task output by picking
individual values out of a list of objects.
Our result selector takes an array of market orders, picks values like price and
puts each of them into a field name based array. The example above is transformed to
{P: [1587324.99], T:[1524], V: [17]}. While this short example doesn’t seem like a big reduction
in size, the ResultSelector allows us to ditch uninteresting fields from the response objects, and lets us save even
more size, by condensing repeated field names into one array name.
We can reconstruct individual market orders by picking the same index from each array and combining them into a new object.
To wrap up this section, here’s the full task definition to fetch the order pages.
"Fetch Pages": {
"Type": "Map",
"ItemsPath": "$.iterator",
"Parameters": {
"page.$": "$$.Map.Item.Value"
},
"Iterator": {
"StartAt": "Fetch Page",
"States": {
"Fetch Page": {
"Type": "Task",
"Resource": "arn:aws:states:::apigateway:invoke",
"Parameters": {
"ApiEndpoint": "xxxxxxxxx.execute-api.us-east-1.amazonaws.com",
"Method": "GET",
"Stage": "prod",
"Path": "/v1/markets/10000063/orders",
"QueryParameters.$": "$"
},
"ResultSelector": {
"P.$": "$.ResponseBody..price",
"T.$": "$.ResponseBody..type_id",
"V.$": "$.ResponseBody..volume_remain"
},
"End": true
}
}
},
"Next": "Aggregate"
}
We could do a preliminary aggregation after the Fetch Page task if we would otherwise exceed 256 KB for the Map state output.
4. Aggregate Data
In the previous step we used a ResultSelector to reduce the size of the task output, and transformed an array of objects
into three distinct arrays with values from each object. In this step, we aggregate the market information.
To do this, we use a Lambda task as shown below.
"Aggregate": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "arn:aws:lambda:us-east-1:xxxxxxxxxx:function:market-data-aggregate",
"Payload": {
"data.$": "$"
}
},
"ResultSelector": {
"aggregated.$": "$.Payload"
},
}
I’ll keep this section short and omit the Lambda function code. Here’s the output of the Lambda function:
{
"aggregated": [
{
"key": "28215",
"price": 1100000,
"volume": 103
},
...
]
}
5. Store Data in DynamoDB
Finally, we store the aggregated records in DynamoDB with a Map state. The table has a partition key which is a
string called pk.
Keep in mind that DynamoDB expects numbers as {"N": "123"} instead of the plain number value. That’s why we use
the method States.Format to turn the number into a string.
"Store Records": {
"Type": "Map",
"ItemsPath": "$.aggregated",
"Iterator": {
"StartAt": "Store Record",
"States": {
"Store Record": {
"Type": "Task",
"Resource": "arn:aws:states:::dynamodb:putItem",
"Parameters": {
"TableName": "MarketData",
"Item": {
"pk": {
"S.$": "$.k"
},
"volume": {
"N.$": "States.Format($.v)"
},
"price": {
"N.$": "States.Format($.p)"
}
}
},
"End": true
}
}
},
"End": true
}
Once Step Functions processed all the records, we should see the result in the MarketData table.
6. Run and Verify
Now let’s run the state machine, and see its result.
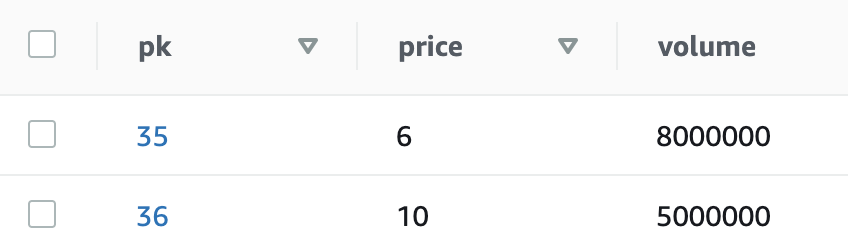
The state machine was successful, and we can see some results in our table.
If we use a different region with more market orders, the time to store data in DynamoDB might take a while, because we get throttled once we exceed 40 concurrent tasks.
Limitations
The parallelization limit was the biggest hurdle. If I can only store 40 to 60 items in parallel, my state machine will take a while to store a couple thousand items. I wasn’t able to work around this limit by using nested Map states, and AWS Step Functions currently doesn’t support batch writes. You can however build nested workflows, where each nested workflow gives you 40 concurrent executions.
Conclusion
After writing two articles I’m not convinced that this is actually a good use for AWS Step Functions. A learning opportunity of course, but probably nothing I would recommend for more advanced production workflows. Fetching data is probably nothing that we need to reinvent. As long as your fetching process can stay within Lambda’s runtime limit, you’re better off using traditional http clients.
Enjoyed this article? I publish a new article every month. Connect with me on Twitter and sign up for new articles to your inbox!