
Archive your AWS data to reduce storage cost
07 Aug 2020AWS announced new storage classes tiers at re:invent 2021. Check out my article about the new storage tiers.
AWS offers a variety of general purpose storage solutions. While DynamoDB is the best option when latency and a variety of access patterns matter most, S3 allows for cost reduction when access patterns are less complex and latency is less critical.
This article describes the available options for archiving data, how to prepare that data for long term archival and how to let S3 transition data between storage tiers.
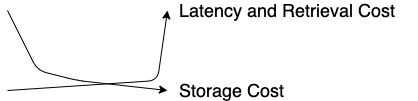
Below you find a table comparing the prices and access latencies as of August 2020.
All prices are for us-east-1. This article focuses on storage cost only.
Prerequisites
You should have an AWS account and gained first experience with DynamoDB or S3. The code snippets are written in Python and are intended to run on AWS Lambda.
Moving Data
As you’ve seen in the previous table, you can achieve significant storage cost reduction, by moving your data to a cheaper storage solution.
There are 3 major paths when archiving data:
- DynamoDB to S3
- S3 Storage Tiers
- Final Archival with S3 Glacier
The first path requires a lambda function, and the others can be achieved without additional glue code. We will however look at data aggregation for small objects, as infrequent access solutions are less suitable for small objects.
DynamoDB to S3
![]()
When to move data from DynamoDB to S3
Moving data out of DynamoDB makes sense when that data is becoming stale, but remains interesting for future use cases.
An example for this are performance metrics. We’re most interested in the recent weeks, but don’t look at data from months ago too much. We still want to keep those around for later analysis or troubleshooting.
How to move data from DynamoDB to S3
To move data from DynamoDB to S3, we can use DynamoDB’s Time to Live (ttl) feature in combination with event streams. This approach requires four steps:
- Specifying a ttl attribute on a DynamoDB table
- Adding a timestamp to records which shall expire
- Activating a stream that DynamoDB will emit deleted records to
- Attaching a lambda to this stream, which checks for
DELETEevents and writes the records into an S3 bucket
The first three steps are covered in my article How to analyse and aggregate data from DynamoDB.
The lambda function to transition records to S3 can be as short as the following snippet:
from datetime import datetime
import boto3
s3 = boto3.resource('s3')
def handler(event, context):
for record in event.get('Records', []):
if record['eventName'] != 'DELETE':
return
payload = record['dynamodb']['NewImage']
# this assumes that there is a partition key called Id
# which is a number, and that there is no sort key
key = record['dynamodb']['Keys']['Id']['N']
date = datetime.now().isoformat()
object_key = f"data-from-dynamodb/{date}/{key}"
body = json.dumps(payload).encode()
s3.Object('my_bucket', object_key).put(Body=body)
This will store deleted records in the S3 bucket my_bucket. No data is lost, the DynamoDB table stays small and you get an instant 90% cost reduction on storage.
S3 Storage Tiers
![]()
If your data is accessed infrequently you can achieve further cost savings by picking the right storage tier.
S3 Lifecycle Transitions allow us to move objects between storage tiers without them leaving the S3 bucket. We define rules where we specify which storage tier an object shall be moved to once it reaches a certain age.

You can read all about the S3 lifecycle transitions on the official AWS documentation.
When to move data between S3 tiers
S3 Standard gives you the most reliability and fastest access speed. If you’re okay with 99.9% availability or you only access your data rarely (e.g. for regulatory checks), then the non-standard tiers can give you a cost advantage. The durability of your data is not affected (unless you pick the One-AZ tier).
You also should aggregate data before moving it to a storage tier other than S3 Standard or S3 Intelligent-Tiering, as there is a minimum capacity charge per object. As a rule of thumb, aggregate your objects until the result is at least 1MB.
How to move data between S3 tiers
Due to the minimum capacity charge we will start by aggregating data. If all of your objects in S3 are already 1MB or more, then you can skip directly to the lifecycle rules. To aggregate objects we can use any compute service (EC2, Fargate, Lambda) to load objects from S3, aggregate them and write the aggregated data back.
import simplejson as json
import boto3
s3 = boto.client('s3')
one_mb = 1024 * 1024
bucket = 'my_bucket'
date_prefix = 'data-from-dynamodb/2020-07'
print("Downloading data")
objects = []
files_response = s3.list_objects(Bucket=bucket, Prefix=date_prefix)
for obj_info in files_response.get('Contents', []):
key = obj_info['Key']
obj = s3.Object(bucket, key).get()
data = json.loads(obj['Body'].read().decode('utf-8'))
objects.append({'key': key, 'data': data})
print("Aggregating data")
aggregated_objects = []
size = 0
aggregator = {}
for obj in objects:
aggregator[obj['key']] = obj['data']
size += len(obj['data'])
if size > one_mb:
body = json.dumps(obj['data']).encode()
s3.put_object(Body=body, Bucket=bucket, Key=f"aggregated/{date}")
size = 0
aggregator = {}
body = json.dumps(obj['data']).encode()
s3.put_object(Body=body, Bucket=bucket, Key=f"aggregated/{date}")
print("Deleting data")
for obj_info in s3.list_objects(Bucket=bucket, Prefix=date_prefix).get('Contents', []):
s3.delete_object(Bucket=bucket, Key=obj_info['Key'])
print("Done")
This code snippet uses boto3 and loads all records from the folder data-from-dynamodb/2020-07, aggregates them, deletes the old data and uploads the new data into the folder aggregated.
Now that we’ve packaged our objects, let’s continue with lifecycle transitions. S3 can be configured to automatically move objects between storage tiers.
In this article we will configure the lifecycle transitions through the AWS console. You can also use the CDK’s LifecycleRules and Transitions to build an Infrastructure as Code solution.
To get started, open your S3 bucket in the AWS console and open the Management tab. Click on “Add lifecycle rule” to configure a lifecycle. By applying the lifecycle rule to the folder aggregated, we only transition data which has been packaged for archival.
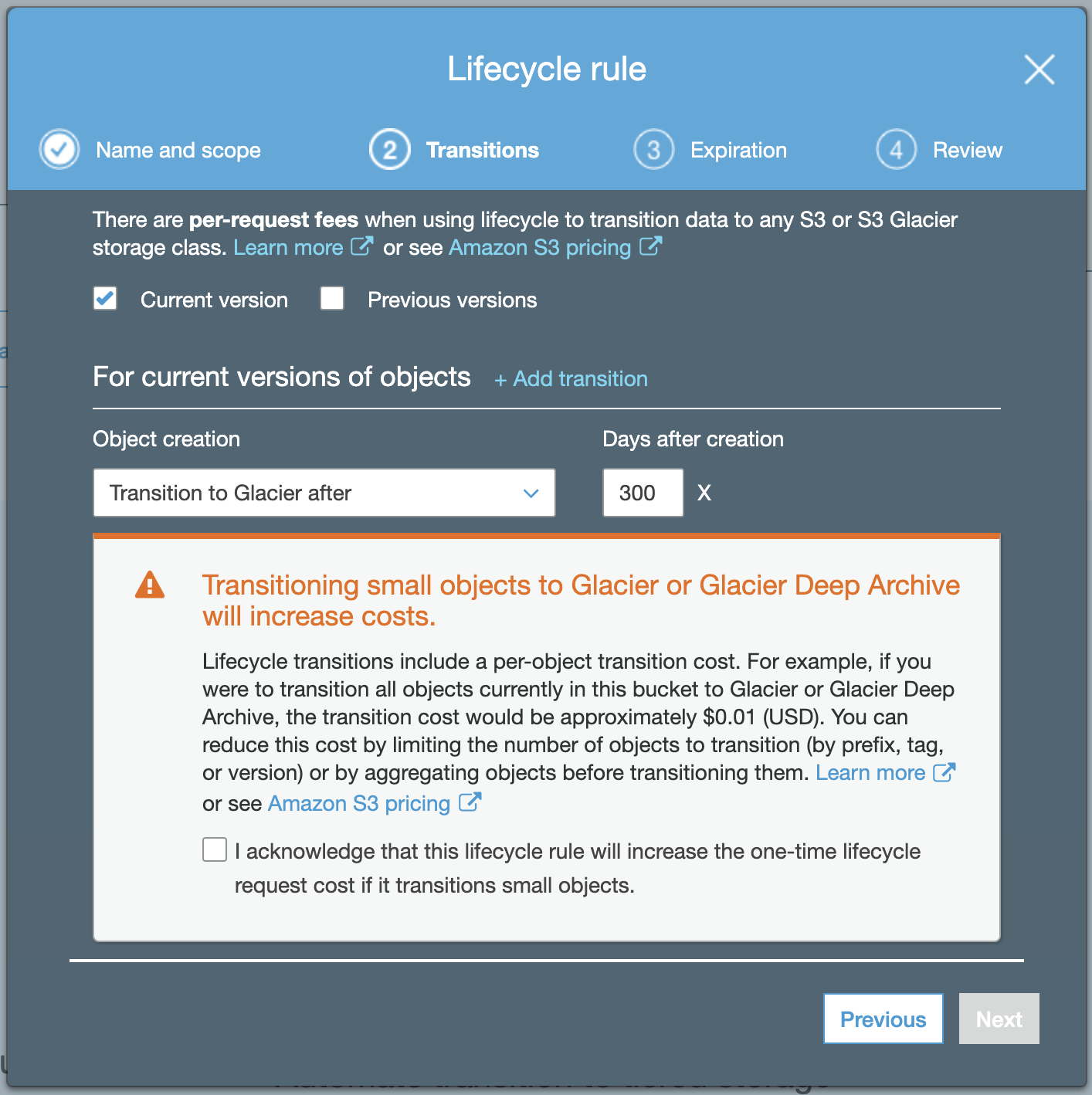
Specify a Transition to Standard-IA (Infrequent Access) after 30 days. We’re assuming here that data will be archived and therefore infrequently accessed, but you can increase this number however you like or pick another storage tier.

Review and complete the lifecycle rule.
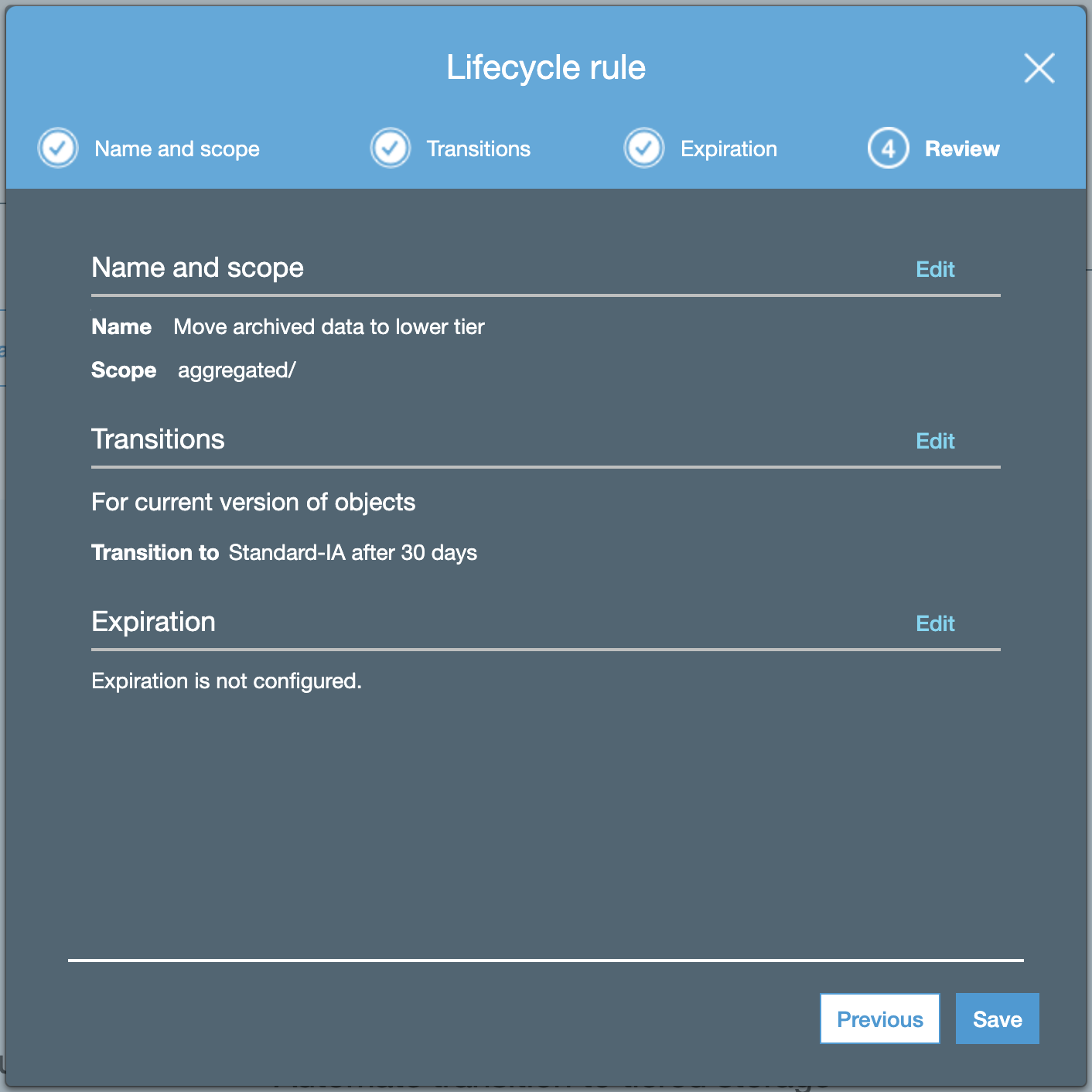
After 30 days you should start see in your bill that some objects are now priced at a less expensive storage tier. If you picked S3 Infrequent Access, that’s another 45% you save for storage.
Data on Ice with S3 Glacier
While we’re only looking at Glacier here, you can apply the same principles for moving data to Intellingent-Tiering, One Zone-IA and Glacier Deep Archive.
![]()
When to move data to Glacier
S3 Glacier and S3 Glacier Deep Archive become interesting options, when you need to store data for a very long time (+5 years) and only access it very rarely (1-2 a year or less).
How to move data to Glacier
As we’ve previously aggregated our data, we can add additional lifecycle transitions to move the data from S3 Infrequent Access to S3 Glacier. Instead of the Infrequent Access tier, now pick a Glacier option and adjust the time before transition accordingly.
That’s it. Your data is now on ice and we get an additional 68% cost reduction on storage.
How to retrieve data from Glacier
To access data that is stored in Glacier, you have to restore a copy of the object. The copy will be available for as long as you specified. The retrieval however can take up to 12 hours.
Next Steps
Do you have big DynamoDB tables? Figure out what data you can archive, and start moving it to S3 for a 90% cost reduction!
Do you already have data in S3? Add a lifecycle transition to a lower tier and aggregate objects if needed.
Further Reading
- Pricing Pages for DynamoDB and S3
- Use Kinesis to move data from DynamoDB to S3
- A tool to concat files in S3, might be helpful to optimize aggregation
- Use S3’s multipart upload to aggregate objects
Enjoyed this article? I publish a new article every month. Connect with me on Twitter and sign up for new articles to your inbox!