
Serverless Cloud is now in Public Preview. Here's my experience!
04 Nov 2021Update: Serverless Cloud has been spun off into Ampt. Since you will have to migrate applications over, I suggest you wait until getampt.com is in general availability.
Serverless Cloud is a new initiative by Serverless Inc. and entered public preview on October 13th, 2021. Many of us already know and love the serverless framework. The Serverless Cloud project makes serverless development even easier and faster.
Check out their documentation if you want to try it out as well.
Earlier in 2021 I joined the beta program and tried out Serverless Cloud in its early stages (v0.15). Being used to minute long deployment times, they already surprised me during the beta. Updates usually took no more than 15 seconds. Since then this dropped to 2 seconds.
Disclaimer: The 2 seconds don’t cover build tooling (like webpack), but only an index.ts file.
One could say “but I can develop that myself, it’s only an API call to deploy code to Lambda”, and that may be true. In my experience the homemade tooling gets neglected over time, and you end up with at least 4 ways to deploy code. If you’re lucky, 2 of them work when you need them. End of rant.
With their announcement of the public preview I wanted to get my hands dirty again. What fits this better than a small and isolated side project?
To test the current state of Serverless Cloud I built a website, where players of EVE Online can compare in-game shipping providers. This requires a website, some APIs, some calls to third party APIs, and a database. I’d say that’s a pretty standard web application.
For the website I chose Next.js as I’m recently exploring this framework. For the backend Serverless Cloud currently lets you
choose between JavaScript or TypeScript. Their suggestion for handling data is to use a data helper, which feels like DynamoDB.
Below you see a list of topics that we will cover in this article. On each step I’ll share my personal experience while building the side project.
- Getting Started
- Building Blocks
- Backend vs. Frontend
- Development Workflow
- Observability
- Stability
- Pricing
- Support
- Wishlist
Getting Started
To get started you can join the public preview, and then follow the quick start.
Once you have the cloud CLI installed, you can run cloud on your terminal to have it automatically deploy changes to your personal instance.
Let’s continue by talking about the building blocks that make up a Serverless Cloud app.
Building Blocks
There are services that use your code, and services that your code uses. For example a CICD pipeline takes your code, and deploys it to an instance. When your code runs on that instance, it calls a database to get data. For this article we will call the services that your code uses “building blocks”.
Serverless Cloud has the five building blocks
- APIs,
- Scheduling,
- Data Storage,
- Data Events, and
- Parameters.
They provide these via the built-in helpers api, schedule, data, and params.
import { api, schedule, data, params } from "@serverless/cloud";
The data events are part of the data helper.
I can’t recall traditional databases like MySQL or PostgreSQL providing data events. That’s why I’m considering data storage and events as different building blocks.
API
If you already have experience with Express, the api helper will feel familiar to you. We specify a route, handle a request object, and send back a response.
import { api } from "@serverless/cloud";
api.get('/ping', (req,res) => {
res.send({ping: 'pong'});
});
You can use this to build any REST API. It also supports CORS via middleware.
Check out the Serverless Cloud API documentation.
My API Experience
I enjoyed how fast one can get started. I don’t have to write YAML or CDK to set up API routes. Instead, I write a function that feels like a Lambda handler, and specify the route as the first parameter.
I don’t remember a significant delay when adding new routes.
I’m used to writing Lambda functions with return values containing body and status code. But with the api helper
I have to use res.send instead. That gave me functions timing out, because I forgot to send a response.
Because I’m so used to it, I would appreciate a mechanism that can map the function’s return value to an HTTP response.
// This is a suggestion. It doesn't work currently.
api.get('/ping', (req,res) => {
return {ping: 'pong'};
});
Scheduler
The scheduler is even simpler. We can set a function to run via a rate or a cron expression.
schedule.every("10 minutes", () => {
// This code block will run every 10 minutes
});
schedule.cron("0 6 * * MON", () => {
// This code block runs every Monday morning at 6 UTC
});
There’s a helper for triggering scheduled functions in integration tests.
Please note that these functions have a default timeout of 60 seconds, and at most 300 seconds (5 minutes). Read more on the docs.
I didn’t use the scheduler for my project.
Data Storage
Serverless Cloud offers NoSQL data storage. It allows you to write items, get individual items, and query for items.
import { data } from "@serverless/cloud";
await data.set('User:michael', {firstname: 'Michael', lastname: 'Bahr'});
const user = await data.get('User:michael');
Furthermore, you can use labels to enable access patterns through fields that are not part of the item’s key. Labels behave like Global Secondary Indexes (GSIs) from DynamoDB.
import { data } from "@serverless/cloud";
await data.set('User:michael',
{ role: 'Admin', ... },
{ label1: 'Admin' }
);
const admins = (await data.getByLabel('label1', 'Admin')).items;
My Data Storage Experience
It looks like the DynamoDB single table design influenced the data helper.
I felt like my previous experience with DynamoDB helped me understand how to use the data helper.
I’m wondering how easy it is for people who don’t have prior experience with DynamoDB or NoSQL in general.
I’m a fan of strong typing, and unfortunately the query string does not provide that.
After reading the documentation of the data helper you may notice that there are a variety of rules that you need to follow.
But there are no compile time validations yet. I suggest some form of linting, or a namespace method like below.
An alternative can be a data modelling library like dynamodb-toolbox.
// This is a suggestion. It doesn't work currently.
data.namespace("Users").set("Michael", {...});
The data helper also accepts a time to live attribute, after which the records are not available through get requests anymore.
I have not yet verified how fast expired data shows up in handlers for data removal events.
DynamoDB’s time to live has a delay.
My project uses data storage to cache results, and keep track of third party api consumption for rate limiting.
After writing a few calls to data I defaulted to using namespaces per entity. For example a route entity would have the namespace route.
The response handling of data calls didn’t match my expectations from DynamoDB.
The structure of a get response object changes based on the number of items that the request returns.
When you retrieve a single item, you get that item as the response. But when you run a query, the result becomes an object holding an items array.
Based on the documentation it looks like this can further change if you want to receive metadata.
const requestCount = (
await data.get(`apirate:push:*`, {limit: 100})
)?.items?.length ?? 0;
Data Events
Data events are like DynamoDB stream handlers, but a big plus is that records arrive deserialized. When our application creates, updates, or deletes an item, the runtime calls our event handler. To write an event handler for data events, we use the following syntax:
import { data } from "@serverless/cloud";
data.on("eventName:key-filter", async (event) => {
// an item has been created, updated, or deleted
});
data.on("eventName:namespace:key-filter", async (event) => {
// an item has been created, updated, or deleted
});
The eventName can be created, updated, deleted, or a wildcard *. The namespace and key-filter are like what we’ve seen in the data queries.
The timeout for data events is 20 seconds, and you can raise it to 60 seconds.
Please be aware that if you call data.set or data.remove in an event handler, you can cause an infinite loop.
The documentation also states that it’s “important to handle errors in your handler, since a failing handler will prevent new events from being processed.”
My Data Events Experience
My side project uses data events to asynchronously run more expensive computations. It gathers more information about a route, so that we can show more advanced information on further requests.
The documentation shows examples where one function handles all events. I had a better experience with building very specific event handlers. Single purpose functions can result in better testability and execution speed.
Data events use a matching syntax similar to the query syntax for the data helper.
The tricky thing here is that you can make a mistake in the query, and only spot the error if your handler doesn’t run.
I don’t know if there’s a good way to address this problem with building blocks from Serverless Cloud.
I feel like a data modelling library might be a good approach to define entities, their keys, and derive query and event handler statements.
Parameters
You import the params helper, and can access the parameters like environment variables via params.KEY.
There’s no service call that you need to await.
import { api, params } from "@serverless/cloud";
api.get("/", (req, res) => {
if (req.headers.API_KEY === params.API_KEY) {
res.send({message: "Hacker voice: I'm in!"});
} else {
res.send({message: "Access denied"});
}
});
You can set parameters through the Serverless Cloud dashboard, either on the organization or application level.
If you have a production secret that should not leak through developer instances, you can override parameters per stage. Define the secret with a placeholder, and then override it in production with the real secret.
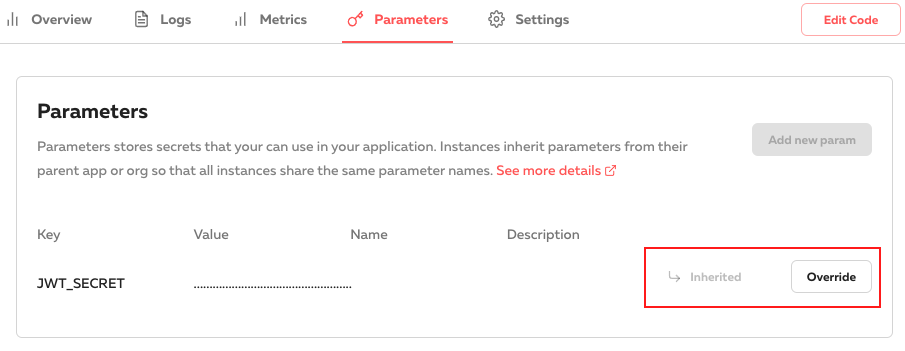
My Parameters Experience
Parameters are as simple as environment variables. They don’t need any service calls, and change immediately when updated through the dashboard.
I first thought that I could only define parameters per organization or application, and needed Emrah from the Serverless
team to tell me that I can override them. Reading all 3 sentences on the parameters documentation might have helped.
Backend vs. Frontend
The entry point for any Serverless Cloud application is the index.ts file. Here we specify all the things we talked above.
Static assets from a ./static folder are automatically served, and API routes take precedence over static files.
This is great for single page applications (SPAs) like React and Vue. For static site generators like Next.js, we have to add API routes that resolve HTML files.
Serverless Cloud currently doesn’t automatically resolve ./dashboard to ./dashboard.html. Below is an example of how you can resolve paths to HTML files:
import { api } from '@serverless/cloud';
import send from 'send';
api.get('/dashboard', (req, res) => {
send(req, './static/dashboard.html').pipe(res);
});
Serverless Cloud’s default project structure has an index.ts file, which it deploys within seconds.
When using Frontend frameworks like React or Next.js you will need some extra setup.
The frontend source code (and its node_modules) folder should live in a dedicated folder (e.g. ./frontend).
The .serverlessignore file lets us exclude the frontend source code from the deployment.
Otherwise, we would hit a size limit when trying to upload the node_modules folder.
Because the cloud tooling expects static files to live in a folder called ./static, we have to build and copy files around.
Here’s an example that I use for Next.js, where the frontend code lives in the folder ./frontend:
next build && next export && rm -Rf ../static && cp -Rf out ../static
The build step above adds about 15 seconds, and may increase as the frontend grows. But this is completely under my control. The deployment to my personal instance usually is below 2 seconds, no matter what I upload.
Let’s stop and appreciate for a moment that we’re still not talking about minute or hour long deployments.
Development Workflow
My favourite workflow starts with local development. From there the code goes to a personal developer instance that integrates with all the cloud services. After that there are staging instances, followed by one or more production instances.
I run unit tests locally, and integration test in the cloud. In my opinion unit tests are for testing business logic code which does not depend on cloud services.
Integration tests and beyond should run on the cloud, because I don’t fully trust emulated service dependencies.
Serverless Cloud encourages you to run everything on the cloud by giving you a cloud test command.
This is necessary when using the building blocks mentioned above.
For unit tests I continue to use my IDE, as it gives me more granularity and debugging control.
As for the frontend development I tried to do most of it locally. Next.js lets me mock API routes with static data.
When we start developing with the cloud command, it sets up a personal instance for us.
We can use that to develop, and write both integration and e2e tests.
As long as the cloud command is active, it automatically uploads changes to our index.ts file and any files in the ./static folder.
If we’re collaborating with a team, we can use preview instances. These let you share code and data with colleagues. From the documentation it looks like you can only share one instance. If I want to continue with developing other features, I would opt for deploying a stage that has a name related to my feature. This lets me work on multiple features, while I wait for colleagues to review my changes.
Once my colleagues reviewed and approved my feature, I would merge it into the main branch and have it go through a CICD pipeline. Serverless Cloud has an example on how to do that with GitHub Actions. I found this easy to set up, without having prior GitHub Actions experience. My pipeline for the side project now has the four steps
- deploying to a preview stage,
- running e2e tests against this stage,
- promoting from preview to production, and
- again running e2e tests against the production stage.
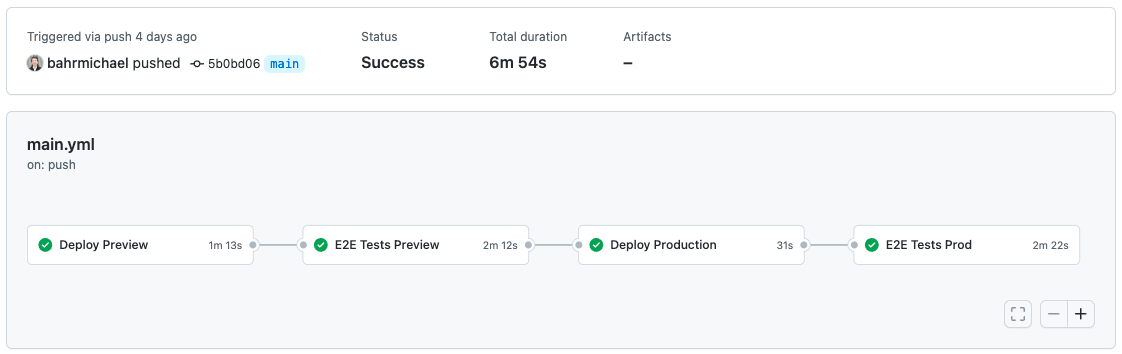
Serverless Cloud’s “bring your own CICD” approach lets you use any CICD provider.
To get your code from your CICD pipeline to Serverless Cloud, you use the commands deploy and promote,
along with a secret to access your instance. Looking at how my experience with GitHub Actions was mostly problem-free,
that’s in my opinion a good path to take. No need to reinvent what already works fine.
They also have an interesting clone command, which copies both code and data from a given stage into your developer instance.
This should be very helpful when debugging emerging problems. But I feel like this increases the necessity for protected stages.
I might not want to allow every developer to copy production data onto their local machines.
Observability
When developing with the cloud command and the personal instance, logs automatically appear in your terminal within seconds.
There’s little friction to adding a console.log here or there, and seeing what happens on your personal instance.
Log streaming is however not available for stages beyond your personal instance.
The dashboard shows metrics such as invocations, errors and average duration. The metrics are available per instance. At the time of writing it was not possible to see metrics on a more granular level, e.g. per API route or scheduled function.
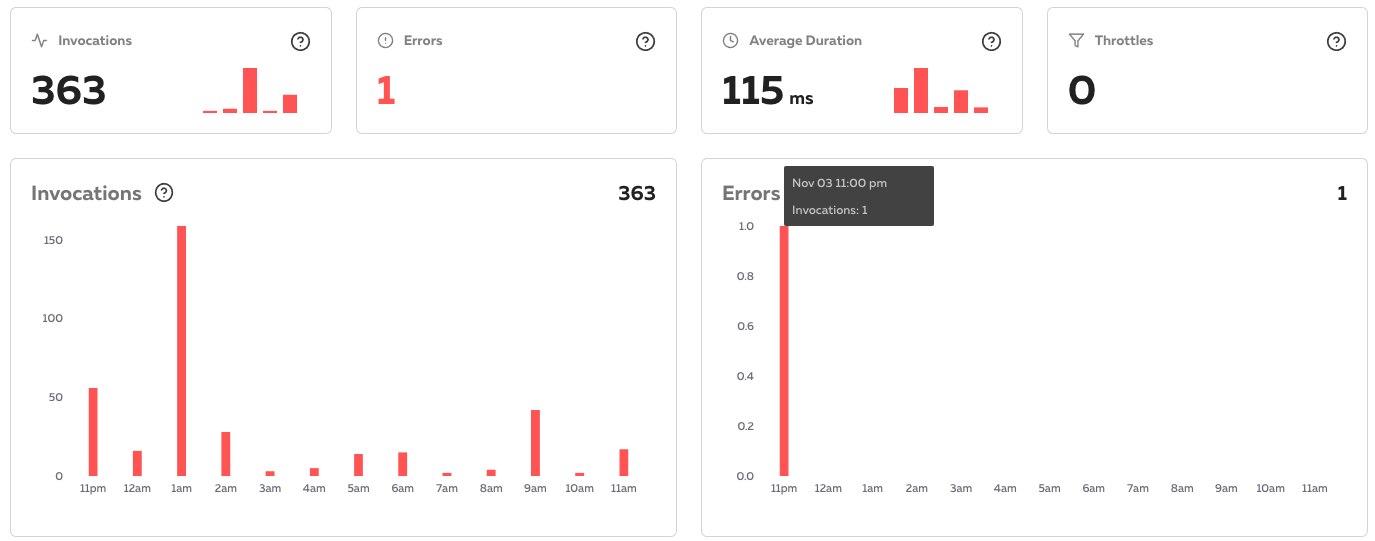
In my example I can see that there are errors in production, but I don’t see which function causes them. When I open the logs, the dashboard freezes until I forcefully close the browser tab. The team behind Serverless Cloud is aware of this problem.
Stability
The deployment stability is flawless. I have not encountered a single failed deployment during my tests for this article.
The instance stability is okay for a public preview. I sometimes see “internal server error” messages when opening the URL of my instance, but I expect them to “just go away” as Serverless Cloud approaches general availability. This applies to both personal instances and stages. I find these stability issues easy to deal with, and they are clearly outweighed by the ease of development. A browser refresh is usually enough.
During development with the personal instance I sometimes face cold starts. These can total up to 10-20 seconds when we need to access static assets and multiple APIs. That’s noticeable, but still a lot faster than waiting minutes for a deployment.
It’s rare that you can say “the website takes longer to load than to deploy”.
Support
Serverless Cloud has a Slack channel on the Serverless Community server. That’s where I go for getting help, and usually within a few business hours get a response. The team is very helpful when I post my problems, even if it turns out I messed up my DNS config.
When I wrote this article, Emrah from the Serverless Cloud helped me root out some issues. Thank you very much! Please let me know if you find more.
Pricing
The free tier is nice for getting started and getting some first hands-on experience. For long term hobby projects you have to decide if you want to upgrade to a paid plan to get a custom domain. But then the paid plan starts at 20$ per month, and cost only grows if you exceed the included quota. There’s no word of expiring free tiers, so there should be no billing surprises for the free tier.
I hope that paid plans don’t impose a limit on how many instances I can have. That’s because I don’t want to batch multiple applications into one, just so that my mostly idle hobby projects can run on a cheaper tier.
I would like to see some control mechanisms for spending with the paid plans. Billing alerts should be the basic minimum, my most favoured approach would be a cap to spending. There’s a limitation for the free plan, so there might be a way to add spending limits for paid plans?
Wishlist
My wishlist revolves around two key aspects: Insight and protection.
Currently, I can only inspect and manipulate data through integration tests and application code. In my example I used the database to cache data. When I insert bad data during development, I can destroy and recreate my personal instance. For production stages I want to use operational tooling instead, which can read and change records in the production database.
The second part of the insight aspect is about metrics and alarms. I would like to see more granular metrics on a per-function basis. With those metrics I want to set up alarms, e.g. for function errors or latency thresholds. When I have alarms I feel more confident that my application won’t break without me knowing it.
Two things that should have some form of protection are stages and secrets.
To protect my production instance I want to prevent accidental deployments. I like the promote command, and would like to prohibit every deploy to production.
Every deployment? No. For hotfixes, I may have to skip that. Having a toggle or “break glass” mechanism on my production instance would be nice for this.
If we continue to think about operational readiness, topics like canaries, traffic shifting, and auto-rollback come to mind. I’m looking forward to seeing where Serverless Cloud draws the line between extending its capabilities, and referring to other providers.
Conclusion
Serverless Cloud has potential to attract developers. It speeds up the development workflow, and manages infrastructure for you. The current state of the public preview is carefully designed for a great experience with building websites, APIs and background jobs. I see great potential for developers who are not yet familiar with serverless. All I have to do here is writing code, and deploying it. I don’t have to learn how to compose various event driven services.
Enjoyed this article? I publish a new article every month. Connect with me on Twitter and sign up for new articles to your inbox!